












マーケティングリサーチの学び場『Lactivator』代表。自動車会社でマーケティングリサーチに従事後、誰でも気軽にマーケティングを学べる場として2012年に本サイトを開設。また故郷:群馬県の活性化の為、2013年より上毛かるたの日本一決定戦『KING OF JMK』を主宰。著書『上毛かるたはカタル』も発売中。
●無料メールで学ぶマーケティング講座配信中⇒こちら
こんにちは。
マーケティングリサーチャーの渡邉です。
今日は『なぜマーケティングには統計学が必要なの?』というシンプルな質問に答えます。
このブログでも統計についてはちらほら触れていますし、また統計学が好きだからマーケティングに興味があるという方も多いと思います。
ただ中には数字が苦手で『どうしても統計を勉強しないといけませんかね?』と考えるマーケッターもいらっしゃり、実際にそういうご相談も多々受けます。
僕の意見を申し上げると、絶対に必要かと言われればそんなことはありません。
統計学の知識はないのに立派な実績をあげているマーケッターは数多く存在しますからね。
ただ、マーケティングというよりもビジネスで勝つ為にはやはり身に付けておくべきスキルです。
今日はそれについてお話します。
まずはおススメの本のご紹介
最初に、統計学がなぜ今後のビジネスで大切なのかを知るのにおススメの本をご紹介します。
『統計学が最強の学問である』西内啓 著

西内さんは東京大学医学部を卒業され、現在は戦略立案コンサルタントとして活躍されています。
この本も2013年に発売され、2014年のビジネス書大賞に選出されておりますのでご存知の方も多いのではないでしょうか。
もしも『統計学』がこの世になかったら
全ての決断は人間の経験とカン
上記の西内さんの本にも紹介されていますし、また昨今(このブログは2020年5月に書いています)の新型コロナウィルスの報道などでもお分かりと思いますが、『統計学』は『疫学』の発展に大きく寄与しています。
『疫学』とは原因不明の疫病の防止を目的とした学問ですが、世界で最初に疫学研究が行われたのは19世紀前半のロンドンで蔓延し十数万人もの死者を出した『コレラ』だと言われています。
当時日本はまだ江戸時代だった訳ですが、既にイギリスでは高等教育を受けた科学者や医者が多数存在しており、コレラ感染拡大防止に向けて様々な知恵を絞り出していました。
ただ『統計学』がまだ確立されていない時代だったので、考え出された彼らの方策はどれも大御所達の経験や勘(カン)に基づいたものだったのです。
ある人は低所得者層の住む不潔な『臭い』地域に住む労働者たちが数多く死亡していた為、その悪臭を取り除く為に大量の消臭剤を撒けと言ったり、またある人は街中の汚物を片っ端から清掃して下水に流せと言ったり。
当然それらの方策は全く効果を発揮しませんでした。
疫学の父:ジョン・スノウの出現
しかしそのあと、後に『疫学の父』と呼ばれるジョン・スノウという外科医がコレラの感染防止について非常にシンプルな論文を発表します。
彼のやったことは以下です。
●コレラで亡くなった人の家を訪問して親族の話を聞き、その環境を観察。
●コレラにかかった人とかかっていない人で何か違いはないかを探索。
●その『違い』に関する仮説が得られたらそれに関するデータを収集、確からしさを検証。
その結果をスノウは細かくまとめているのですが、その中で一番端的にコレラの予防方法を論じているのが下記の表です。
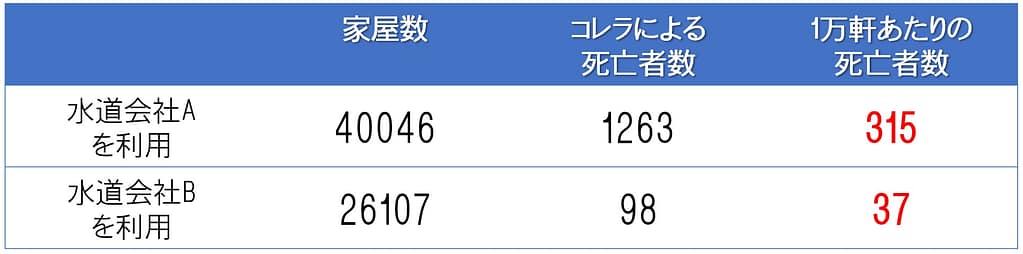
当時ロンドンでは複数の水道会社が営業していたそうですが、上記は貧困層の居住地域で利用されている水道会社別の家屋数とコレラ死亡者の集計結果になります。
これを見ると、水道会社Aを利用した家では調査期間中に1263名の死亡者が確認されたのに対し、水道会社Bを利用した家では98名と少ない事が分かります。
これをフェアに比較する為に『1万軒あたりの死亡者数』に調整して比較すると、水道会社Aを利用していた家屋では315名、水道会社Bを利用していた家屋では37名ということになります。
水道会社Aを利用している家では水道会社Bより、実に8.5倍も多かった訳です。
流石に水道の違いで8.5倍もリスクが異なるならば、そこには何か理由があるはずです。
この時点では詳しい理由は分かりませんが、結果からスノウは、
『水道会社Aの水を使うのをしばらく止めよう!』
という提案をしたのです。
ただ、この主張はあろうことか、当時の学会や行政から却下されてしまいます。
当時はまだ統計という概念が無かった時代なので、彼の主張は『科学的ではない』と結論付けられてしまったのですね。
しかしいくつかの地域ではスノウの結果を信じてA社の水の使用を停止した結果、コレラの発症率が劇的に減少していきました。
この30年後、ドイツの細菌学者であるロベルト・コッホがコレラの病原体である『コレラ菌』を発見。
そしてそれが水道会社Aの水に多く生息し、コレラ菌を含む水を飲む事でコレラに感染する事も証明されたのです。
水道会社Bはテムズ川の上流から採水しているのに対し、水道会社Aは下流から採水していました。
そのテムズ側にはコレラに感染した市民の排泄物が流れており、その為水道会社Aの水が感染を増幅させていたのです。
統計学が教えてくれること
『取り急ぎ』の対策が打てる
おそらく現代社会で初めてコレラが蔓延し、上記のようなデータが出てきたら、
『よし!なぜ水道会社Aの水を引いている家で感染率が高いのかはわからないが、取り急ぎAの水を大至急止めよう!A社の水質をチェックするのはその後だ!』
と判断する人が多いと思いますが、統計学が浸透してない当時はそのような決断ができなかったのです。
しかし、もしコレラの原因となる菌を発見して、それが水道会社Aの水の中に多く存在している事を確認してから対策を打つ・・・なんてことをしていたら、おそらくもっと多くの方が犠牲になっていた事でしょう。
このように統計学は疫学に対して、真犯人(真の原因)が不明な状態でも『取り急ぎ』の感染防止策が打てて1人でも多くの命を救えるというメリットをもたらしたのです。
ちなみにその数十年後、オーストリアのメンデルがエンドウマメの研究により遺伝の基本である『メンデルの法則』を発表しました。
この研究も統計に基づいて遺伝の規則性を説明しているのですが、当時の植物学会ではほとんど相手にされませんでした。
実は、統計学が医学や科学の分野に浸透してきたのは20世紀に入ってからです。
統計学がもたらすマーケティングへのメリット
さて、その統計学がマーケティングに活用されるようになったのは更に後のことです。
もちろんマーケティングと疫学は異なり、失敗したからといって多くの人が亡くなるという事はありません(笑)
しかし似ているのは『起こっている現象に対する真の要因が掴みにくい』という点です。
上の事例でいうと、コレラでは『コレラ菌』という病原体を発見するのに30年かかっています。
そこまで大げさではありませんが、マーケティングでもA/Bテストをやった際、広告Aに比べて広告Bの方がお客様の反応が良かったという結果が統計的に分かったら、すぐに広告Aを採用できますよね。
『その結果だけではダメだ!なぜ広告Aの方が反応が良いのかを論理的に説明できるようになるまで判断はできない!』
なんて人は経営者として相応しくありません。
広告はキャッチコピーや色、デザイン、配置など様々な要素で成り立っていますので、反応率の良さを論理的に解明しようとしたらかなりの時間を費やしてしまいます。
もちろん論理も重要ですが、早期に収益を上げる為には取り急ぎ広告Aを採用すべきです。
こんな感じで、正確な判断をスピーディに下す為には統計学が絶対必要なのです。
統計学の種類
ちなみにお話ししておくと、統計学といっても様々な種類があります。
代表的なものは以下の3つです。
1.記述統計学
2.推計統計学
3.ベイズ統計学
一番親しみやすい『記述統計学』
記述統計学は「データの特徴を簡単にわかりやすく表現する」というものです。
例えば、あるスポーツジムのサービス内容を会員さんに評価してもらい、男性と女性で比較するというのは記述統計学(descriptive statistics)になります。
どんな風に評価するかはその時々で違いますが、一般的には評価結果を性別で分けて平均し比較するという感じでしょうか。
これは言い換えれば、平均化という方法でデータの特徴を分かりやすく表現している訳です。
平均の他にも分散や標準偏差といった数値で表現する事もありますし、またグラフや表を作成してそのデータの様々な特徴を抽出することも記述統計学です。
しかし記述統計学だと、分析できないことがたくさんあります。
例えばスポーツジムの例だと、
●新しいサービスを作る為、日本人の平均ウエストサイズを知りたい。
●その新しいサービスを利用するとどのくらいウエスト細くなるのか知りたい。
などです。
日本人の平均ウエストサイズを知るのであれば、全国民にアンケート調査を行ってサイズを答えてもらわないといけません。しかしそれは不可能ですよね。
従いまして全国民のデータがない以上は記述統計学を用いても分からないのです。
また新店舗を立ち上げた時の売上げというのは未来のことなのでデータを入手するのは不可能です。
これもデータがないので、記述統計学では推測できません。
このように、記述統計学ではデータがないと何もできないということになります。
先程も申し上げた通りデータを分かりやすく表現するという学問なので当然なのですが、記述統計学ではこれが限界なのです。
その為に生まれたのが『推計統計学』という考え方です。
限られたデータから推測する『推計統計学』
推計統計学(inferential statistics)とは、限られたサンプル(標本)から母集団全体の特徴を推測するという学問になります。
先程の日本人の平均ウエストサイズの例で言えば、日本人全体の人口から必要最低限のサンプルデータを集め、その結果から推測するという事です。
記述統計学では母集団とサンプルの区別をしていませんでした。ほとんどの場合は母集団=サンプルなので、統計的に示せるのはサンプル内にとどまる訳です。
一方推計統計学では集められたデータを大きな母集団の中の一部と考え、そしてそこから母集団を推測しようとします。
また『その新しいサービスを利用するとどのくらいウエスト細くなるのか知りたい』という風に未来を予測したい場合、これは何人かの方にサービスモニターとなってもらって利用前後のウエストの変化を計測し、その関係性を利用すれば『回帰分析』という方法を使って推測できます。
詳しい説明をここで行うと膨大な量になるのでここでは割愛しますが、推計統計学を使えば一部のサンプルから色々なことを推測できるという事を理解して下さい。
今後の技術発展の要『ベイズ統計学』
そして近年注目されているのが『ベイズ統計学』です。
これは上記2つの統計学とは全く違う考え方をするかなり特殊な学問で、推計統計学はサンプルを分析して母集団を推測のに対し、ベイズ統計学はサンプルを必ずしも必要とはせず、データ不十分でも何とかして確率を導くという方法です。
超簡単に言うととりあえず何かしらの値を確率として使い、新しい情報を得たらどんどんアップデートしていくという形を取ります。
これは人工知能(AI)や機械学習の分野で使われる方法です。
将棋のプロ棋士とAI棋士が対戦したなんていうニュースをよく聞きますが、これは過去に行われたプロ棋士同士の対戦結果(棋譜)をデータとして取り入れ、『次にどんな手を打てば一番勝つ確率が高くなるか?』を計算している訳です。
そしてこれは対局が増えれば棋譜も増えていきますから、これらのデータを取り入れれば取り入れるほど強くなるはずです。
ベイズ統計についても、今後別のブログで詳しくお話しします。
まとめ
このように統計学という学問は100年以上前からあったのですが、データを解析する為の機械がなかった為になかなか発展しませんでした。
それでも昔の学者達は紙とペンで計算していた訳ですが、その為に膨大な時間が費やされていたのですね。
しかし、コンピューターが登場すると面倒な計算は全てコンピューターにやらせればいいので、そこから急激に発展してきます。
ここ最近はビッグデータなんてものも注目されてきていますが、これまで膨大すぎて計算なんて到底できなかったデータの処理がコンピュータにより可能になりました。それによって、これまでは放っておかれていたデータから様々な分析を行えるようになったのです。
確かに理解するのが難しい部分もあるのですが、分かり始めれば楽しい学問ですので、是非毛嫌いせずに勉強してみて下さい。
[ShortCode1]














